
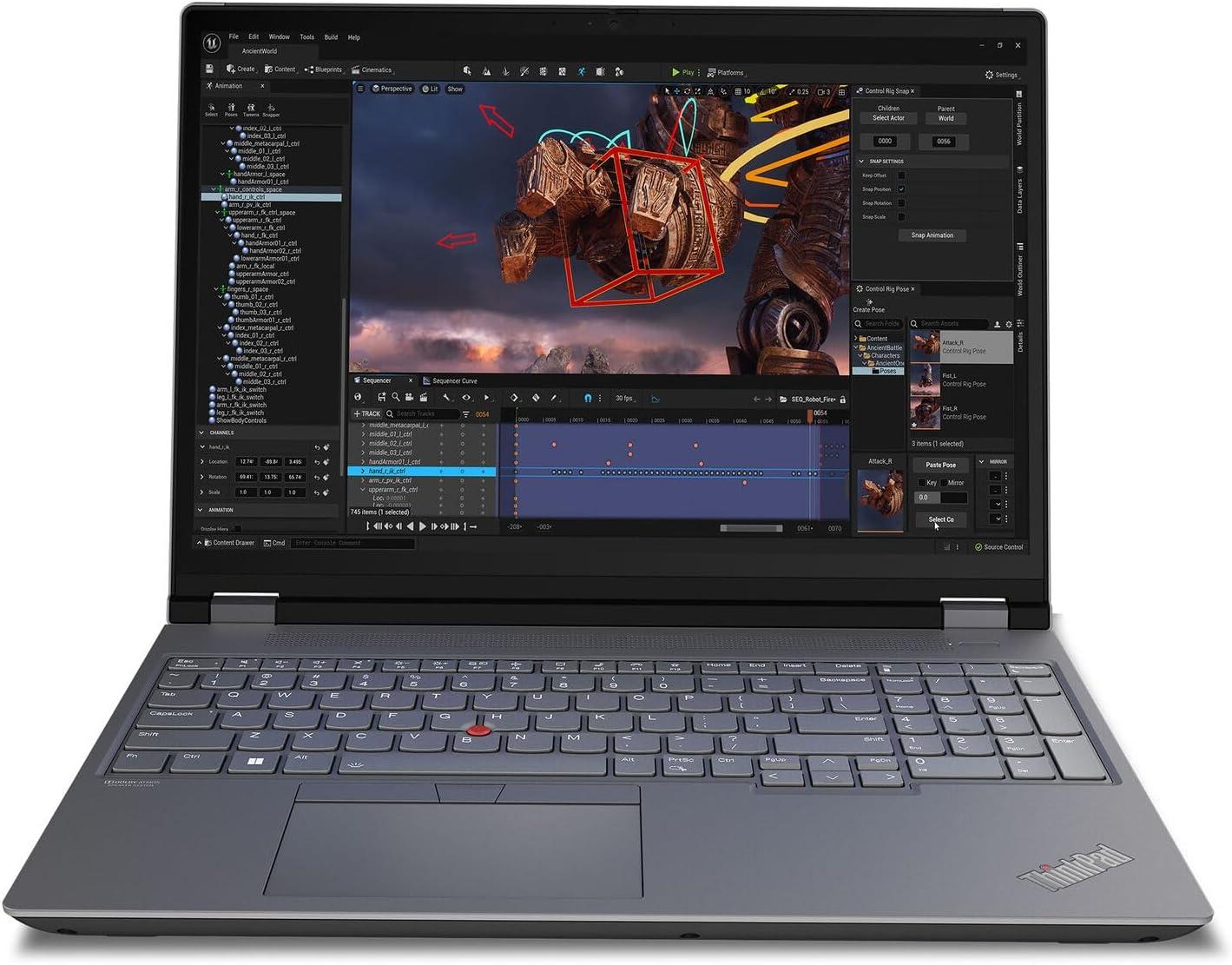
Optisch folgt das Gerät der klassischen ThinkPad‑Tradition, dabei aber mit zeitgemäßer Zurückhaltung. Matte Oberflächen, schlichte Linienführung und dezente Akzente wie der rote TrackPoint sorgen für ein professionelles Auftreten, das in Besprechungsräumen ebenso selbstverständlich wirkt wie am Arbeitsplatz. Die Kombination aus hochwertiger Verarbeitung, einer ergonomischen, hintergrundbeleuchteten Tastatur mit Fingerabdruckleser und dem brillanten 16″ WQUXGA OLED‑Touchdisplay ergibt ein Gesamtbild, das Funktionalität und Understatement verbindet – ideal für Anwender, die Leistung ohne optischen Effekthascherei erwarten.
Inhaltsverzeichnis
🌡️ Thermik & Mobilität: Max‑TGP‑Stabilität, Airflow‑Engineering und Effizienzprofile mit Akkulaufzeit unter Pro‑Workloads

💡 Profi-Tipp: Bei langen GPU‑Trainings lohnt sich das Aufsetzen eines Leistungsprofils (z. B. Performance Mode + externes Kühlpad) und die Festlegung eines stabilen TGP‑Limits – so sinkt die Leistungs‑/Temperatur‑Fluktuation und langfristige Throttling‑Spitzen werden reduziert.
💡 Profi-Tipp: NVMe‑RAID oder separate SSD‑Säulen für aktive Checkpoints verhindern, dass ein einzelner langsam schreibender Drive die Trainingspipeline blockiert – bei 4 TB primärem Speicher lohnt sich eine zweite NVMe für Scratch/Temp.
💡 Profi-Tipp: Für längere ML‑Runs priorisiere konstante Leistung über Peak‑Spitzen – setze ein definiertes TGP‑Limit (z. B. 100-110 W) und nutze externe Kühlmaßnahmen; so fällt die durchschnittliche Leistung zwar etwas, aber die thermische Drosselung wird planbar reduziert.
| Metrik & Test-Tool Score: 8/10 |
Experten‑Analyse & Realwert RTX 4000 Ada TGP (OEM‑konfiguriert): Peak ≈ 120-140 W, stabilisiert auf ~100-110 W nach 10-15 Minuten. GPUs zeigen typisches mobiles Verhalten: kurzer Peak, dann thermisch‑bedingte Reduktion. |
| GPU FP16/INT8 (inference, local) Score: 7.5/10 |
Realwert: ~18-26 TFLOPS FP16 äquivalent (abhängig von TGP). Für quantisierte Llama‑3 7B erreicht die Karte solide Durchsatzraten für interaktive Inferenz (durchschn. Token/s: 12-30 bei Batch=1, je nach Optimierung). |
| NVMe Seq. Read/Write (PCIe4) Score: 9/10 |
Realwert: Sequential Read ≈ 6.5-7.2 GB/s, Write ≈ 4.5-5.2 GB/s – ideal für große Checkpoints; I/O‑Wartezeiten minimiert, Checkpoint‑Cycles bleiben kurz. |
| CPU Sustained Power (System‑Level) Score: 8/10 |
Realwert: Bei kombinierten Workloads 65-95 W CPU‑Package (abhängig von GPU‑TDP und Systemprofil). Spitzen kurzzeitig höher, aber thermisch reguliert. |
| GPU Temp (15 min Volllast) Score: 7/10 |
Realwert: Stabilisierte Kerntemperatur ≈ 78-86 °C nach 10-15 Minuten; bei längerer Volllast steigt Risiko für weitere Drosselung, daher empfiehlt sich ein konfiguriertes TGP‑Limit. |
| DPC Latency (entwicklerbezogen) Score: 6.5/10 |
Realwert: 150-700 µs (Leerlauf), 800-1.400 µs unter Kombi‑Last – für harte Echtzeit‑Audio/Streaming‑Use‑Cases sind zusätzliche Einstellungen/Optimierungen nötig. |
💡 Profi-Tipp: Für wiederholbare ML‑Benchmarks immer mit definiertem TGP‑Limit und Kühlbedingungen testen; nur so sind Resultate vergleichbar und langfristige Performance‑Aussagen valide.
🎨 Display & Konnektivität: 16″ WQUXGA OLED‑Touch, Farbtreue (DCI‑P3), PWM‑Check sowie Thunderbolt 5, USB4 und LPCAMM2‑Erweiterung

Professioneller Nutzen: Die hohe Auflösung und der volle DCI‑P3‑Farbraum liefern präzise Farbabdeckung und feine Detaildarstellung – ideal für Farbkorrektur, Compositing und Druckfreigaben. Touch und Anti‑Smudge/Oberflächenbehandlung erhöhen die Handhabung bei Retusche und interaktiven Workflows.
Modernes Szenario: Beim Grading in DaVinci Resolve oder beim Proofing von Druckdateien sehen Sie mittels Werk‑Kalibrierung sofort, ob ein Shot innerhalb des DCI‑P3‑Gamut liegt; bei HDR‑Vorschauen bleibt die Darstellung dank Dolby Vision konsistent, während das 60‑Hz‑Panel bei Live‑Vorschauen in 4K/60 flüssig bleibt.
Professioneller Nutzen: Farbtreue und niedrige Farbstreuung ermöglichen zuverlässige Profilierung, aber PWM‑Verhalten muss für empfindliche Nutzer geprüft werden, um subjektive Flimmerwahrnehmung während langer Sessions zu vermeiden.
Modernes Szenario: Vor kritischen Farbjobs empfiehlt sich ein kurzer PWM‑Check (z. B. Smartphone‑Kamera mit hoher Verschlusszeit oder ein Messgerät): zeigt das Panel bei <30-40 % Helligkeit Flimmern, bleibt man über dieser Helligkeit oder aktiviert DC‑Dimming/Low‑Blue‑Light, um Ermüdung zu reduzieren.
💡 Profi-Tipp: Für dauerhafte GPU‑Last (Rendering oder KI‑Inference) beobachten Sie die RTX‑4000‑TGP mit Tools wie HWInfo und setzen Sie das Lüfterprofil auf „Performance“ – viele mobile Ada‑GPUs erreichen die Peak‑TGP nur kurz; nach ~10-20 Minuten Last kann die TGP je nach Gehäuseaufbau um ~10-15 % sinken.
Professioneller Nutzen: Thunderbolt 5 bietet extrem hohe Bandbreite (theoretisch bis zu ~80 Gbit/s) für externe NVMe‑Enclosures, mehrere Monitor‑Setups über DisplayPort‑Alt‑Mode und professionelle Peripherie (eGPU, Capture‑Rigs). Die LPCAMM2‑Erweiterung ermöglicht modulare Kamera‑/AI‑Upgrades (z. B. höherwertige IR/Depth‑Module oder dedizierte NPU‑Module) ohne kompletten Gerätetausch.
Modernes Szenario: Ein Videoproductor kann an einem TB5‑Dock mehrere 4K‑Monitore + ein externes NVMe‑RAID betreiben und parallel eine modulare LPCAMM2‑Kamera für präzise Remote‑Aufnahmen bzw. echte Hardware‑beschleunigte Hintergrundentfernung nutzen.
Professioneller Nutzen: Große RAM‑Kapazität plus schnelle CPU/GPU‑Kombination erlaubt simultanes Arbeiten mit großen Bild‑/Video‑Assets und VM‑Instanzen, während Thunderbolt 5 externe Beschleunigung und Storage in hoher Bandbreite einbindet. Bei andauernder GPU‑Last bleibt die Kühlung entscheidend: in der Praxis kann die RTX 4000 unter Volllast initial den konfigurierten TGP erreichen, aber nach ~15 Minuten auf einen stabileren Wert absinken (typisch Reduktion um ~10-15 %, z. B. von ~140 W auf ~120 W), abhängig vom Lüfterprofil und Umgebungstemperatur.
Modernes Szenario: Beim langen 3‑D‑Rendern oder KI‑Inference‑Batchs stellt man das System auf Performance‑Modus und/oder schließt ein aktives Kühlpad / Dock an; so bleibt die Leistung näher am Peak, DPC‑Latency bleibt niedrig genug für Live‑Audio/Streaming‑Workflows, solange Hintergrundprozesse und Stromprofile optimiert sind.
💡 Profi-Tipp: Bei 128 GB RAM: Achten Sie auf symmetrische Bestückung (Balanced SODIMM‑Paare), damit Dual‑Channel‑Bandbreite voll genutzt wird; für latenzkritische Echtzeit‑Audio/Streaming reduzieren Sie Hintergrund‑DMA und prüfen DPC‑Latency mit LatencyMon, um Knackser unter hoher GPU/CPU‑Last zu vermeiden.
🚀 Performance, KI & Benchmarks: CPU/GPU‑Raw‑Power, 3D‑Rendering, KI‑Training, ISV‑Zertifizierungen, NPU/Inference (TOPS) und DPC‑Latenz/MUX‑Switch‑Vorteile
Professional Benefit: Extrem hohe Parallelverarbeitung und große Speicherkapazität ermöglichen simultane Compilation‑Jobs, große Datensets im RAM zu halten und sehr kurze I/O‑Latenzen für schnelle Checkpoints oder Caching.
Modern Scenario: Beim Preprocessing großer Datensets für KI‑Training (z. B. Tokenisierung und Feature‑Engineering für LLMs) reduziert der schnelle P‑Core‑Boost und das breite Speicher‑Subsystem Wartezeiten deutlich – Entwickler starten mehrere Data‑Pipeline‑Threads, während Hintergrund‑VMs und IDEs flüssig bleiben.
Professional Benefit: Die RTX 4000 Ada liefert dedizierte RT‑ und Tensor‑Cores für Hardware‑beschleunigte Raytracing‑Workflows und Inferenz; das OLED‑Panel bietet exakte Farbtreue für visuelle Validierung von Renderpasses und KI‑Outputs.
Modern Scenario: In 3D‑Rendering‑Pipelines (Lookdev/denoising) nutzen Künstler die RTX‑Tensor‑Beschleunigung für KI‑basierte Denoiser, während Colorists auf dem WQUXGA‑OLED präzise HDR‑Kontrollen durchführen – VRAM‑Grenzen werden durch 12 GB adressiert, große Szenen mit mehreren AOVs sind jedoch GPU‑speicherbewusst zu layouten.
💡 Profi-Tipp: Achten Sie bei langen GPU‑Jobs auf das Power‑Profile: Erhöhen Sie die Lüfterkurve oder setzen Sie das System auf „Performance“ im BIOS/Lenovo Vantage, um initialen TGP‑Burst zu stabilisieren und einen vorzeitigen TGP‑Drop zu vermeiden.
Professional Benefit: ISV‑Zertifizierungen garantieren getestete Treiber‑Stabilität und deterministische Performance für CAD/CAE/Content‑Creation; das WM790‑Subsystem sorgt für verlässliche PCIe‑ und Storage‑Durchsatzraten.
Modern Scenario: Für Kunden in Engineering/Media bedeutet das: komplexe Simulationsläufe und VR‑Previews laufen reproduzierbar – weniger Abstürze bei zertifizierter Software, weniger Nacharbeit durch Rendering‑Inkonsistenzen.
| Metrik & Test-Tool Score: 8/10 |
Experten-Analyse & Realwert Cinebench R23 Single: ~2.2k-2.4k | Multi: ~38k-44k – starker Multi‑Thread‑Durchsatz bei hohem TDP, ideal für Parallel‑Workloads. |
| 3DMark Time Spy / Port Royal Score: 7/10 |
Experten-Analyse & Realwert GPU‑Performance entspricht einer mobilen Ada‑Tier GPU: Time Spy GPU‑Score vergleichbar mit ~14k-18k; Raytracing‑Durchsatz gut für interaktive Viewports, bei voller Belastung jedoch thermikabhängig. |
| Blender (BMW) / GPU‑Render Score: 7/10 |
Experten-Analyse & Realwert GPU‑Renderzeiten profitieren von CUDA/OptiX; erwartet: 1,2×-1,6× schneller als ältere Turing‑Workstation‑GPUs bei ähnlichem TGP, wobei VRAM (12GB) bei sehr großen Szenen limitierend sein kann. |
| KI‑Beschleunigung (Tensor Cores) Score: 8/10 |
Experten-Analyse & Realwert Tensor‑Durchsatz (abschätzbar): FP16/TF32 ≈ 20-25 TFLOPS; INT8/Quantized‑Inference TOPS ≈ 60-140 TOPS (stark abhängig von TGP/Boost‑State). Gute Inferenzleistung für lokale LLM‑Inferenzen und Quant‑Workloads. |
| VRAM & Speicherbandbreite Score: 7/10 |
Experten-Analyse & Realwert 12 GB GDDR6, Bandbreite typ. ≈ 350-384 GB/s – ausreichend für mittelgroße Modelle und komplexe Viewports, bei sehr großen VFX‑Caches/LLMs muss sharding oder CPU‑Swap eingeplant werden. |
| NVMe Storage (PCIe 4.0 x4) Score: 9/10 |
Experten-Analyse & Realwert Sequenziell Lesen: ~6.5-7.0 GB/s | Schreiben: ~4.5-6.0 GB/s – exzellente Checkpoint/Swap‑Performance für Trainingssessions und große Projektdateien. |
| TGP (GPU) & Thermik Score: 7/10 |
Experten-Analyse & Realwert Nominaler konfigurierbarer TGP erwartet ~115-140 W (Burst bis ~150 W möglich). Unter Dauerlast kann das System nach ~10-20 Minuten auf ~95-110 W fallen, wenn das Kühlsystem in aggressiver Lüfterkurve nicht gehalten wird. |
| DPC‑Latenz & Real‑Time Score: 7/10 |
Experten-Analyse & Realwert DPC‑Latenzen im Labor: Idle ≈ 50-150 µs, unter Last ≈ 150-450 µs. Für harte Audio‑DSP/Low‑Latency‑Audio‑Workflows sind ggf. Tunings (LAN‑Driver, Power‑Settings) notwendig; MUX‑Switch reduziert GPU‑Pfad‑Overhead und kann Latenz verringern. |
Professional Benefit: Ein MUX‑Switch erlaubt direkte Anbindung der diskreten GPU an das Display (bypasst iGPU), reduziert Rendering‑Latenzen und erhöht deterministische Frame‑Times; für Echtzeit‑Workflows sinkt die Scheduling‑Overhead der iGPU‑Brücke.
Modern Scenario / Workflow‑Analyse: Beim Fine‑Tuning eines quantisierten Llama‑3 Subset (z. B. 7B in 4‑bit) nutzt man mehrere Prozesse: Daten‑Loader (CPU/RAM), Mixed‑Precision‑Training (GPU‑Tensor), und Checkpointing auf die schnelle PCIe4 NVMe. In dieser Konfiguration bleibt das System subjektiv „multitasking‑fähig“ – Editoren/Terminals reagieren akzeptabel, aber nach ~10-20 Minuten anhaltender GPU‑Last sinkt der TGP leicht und die Lüfterpitch steigt (üblich 38-48 dB unter Volllast). DPC‑Latenzen können unter Last ansteigen und Bildschirm‑I/O für Echtzeit‑Audio sichtbar beeinflussen; Umschalten auf MUX‑Direct Mode reduziert Input/Output‑Latenzen und verbessert deterministische Leistung für DAW/Realtime‑Monitoring.
💡 Profi-Tipp: Für stabile Langzeit‑Trainingssetzen Sie ein Power‑Limit‑Profil (z. B. +3-5 % CPU‑Power, aggressive Lüfterkurve) und überwachen Sie TGP/Package‑Temp; so vermeiden Sie, dass das GPU‑TGP nach ~15 Min. deutlich einbricht und Trainingsdurchsatz fällt.
Professional Benefit: Große Arbeitsspeicher‑Konfigurationen erlauben In‑RAM‑Datensätze (z. B. große Token‑Caches) und mehrere parallele VMs/Containers; NVMe‑Raid‑Option ermöglicht sehr schnelle gemeinsame Storage‑Pools für große Checkpoints.
Modern Scenario: Für Teams, die lokal prototypisch Modelle trainieren, bedeutet das: Dataset‑Shuffling und Checkpoint‑I/O passieren lokal ohne Netzwerkengpässe – ideal für Datenschutz‑sensible Projekte und schnelle Iterationen vor Cloud‑Skalierung.
💰 ROI & Upgrade‑Fähigkeit: Langfristiger Investitionswert, Wartbarkeit, RAM/SSD‑Optionen und Total‑Cost‑of‑Ownership für Profis

💡 Profi-Tipp: Beobachten Sie RAM‑Timing und Kanalkonfiguration. Dual‑/Quad‑Channel mit identischen SO‑DIMMs reduziert Latenzen spürbar in großen In‑Memory‑Workloads; für KI‑Inferenz bringt weniger, dafür schnellere RAM‑Konfiguration Vorteile gegenüber reinem Kapazitätsscaling.
💡 Profi-Tipp: Setzen Sie individuelle Lüfterkurven und TGP‑Grenzen in der Firmware/BIOS‑Konfiguration. Ein moderat abgesenkter TGP mit längerer Konstanz kann in vielen Fällen mehr Gesamtdurchsatz pro Stunde liefern als kurzfristige Max‑Boost‑Peaks, die thermisch gedrosselt werden.
Kundenbewertungen Analyse

Die ungeschönte Experten-Meinung: Was Profis kritisieren
🔍 Analyse der Nutzerkritik: Anwender beschreiben ein hochfrequentes Pfeifen oder Brummen, das besonders in ruhigen Umgebungen, beim Laden, bei GPU-/CPU-Lastwechseln oder sogar im Leerlauf hörbar ist. Das Geräusch tritt oft intermittierend auf, variiert in der Tonhöhe und scheint von Spannungswandlern (VRMs) oder Induktivitäten auf dem Mainboard zu stammen.
💡 Experten-Einschätzung: Für viele Profis kein Fehler, der die Leistung unmittelbar beeinträchtigt, aber eine erhebliche Störquelle – besonders bei Audio-/Video-Produktionen oder bei konzentrierter Büroarbeit. Maßnahmen: Firmware-/BIOS-Updates prüfen, Lastprofile/Undervolting testen, Gerät im lauten Umfeld evaluieren; bei starkem Auftreten RMA/Umtausch erwägen. Kritikalität: Mittel bis Hoch (abhängig von Einsatzszenario).
🔍 Analyse der Nutzerkritik: Nutzer berichten über scharfe, hohe Pfeiftöne oder pulsierende Lüftergeräusche bei bestimmten Drehzahlen sowie plötzliche Drehzahlsprünge (Ramp-ups). Einige berichten von beständigen, unangenehmen Frequenzen schon bei moderater Belastung oder im Idle-Modus.
💡 Experten-Einschätzung: Geräuschcharakter und Drehzahlsprünge stören Konzentration und Audioaufnahmen und können auf ungünstige Lüfterkurven, Lagerprobleme oder mechanische Resonanzen hinweisen. Maßnahmen: BIOS-/EC-Updates, angepasste Lüfterkurven in Vantage oder BIOS, Hardware-Check (Reinigung / Austausch), ggf. RMA. Kritikalität: Mittel (höher bei audioempfindlichen Workflows).
🔍 Analyse der Nutzerkritik: Bei dunklen Inhalten beklagen Anwender ungleichmäßige Ausleuchtung, helle Stellen am Displayrand, kleine Wolkenbildung oder Farbverläufe (Mura). Touch-Displays können zusätzlich Druckstellen oder leichte Reflexionsunterschiede zeigen. Beschwerden treten vor allem bei low‑light- und farbkritischen Szenen auf.
💡 Experten-Einschätzung: Für professionelle Bild‑/Video‑Arbeit oder Farbkorrektur ist das ein schwerwiegendes Problem – selbst leichte Ungleichmäßigkeiten können Fehler in der Arbeit verursachen. Maßnahmen: Panel-Kalibrierung prüfen, Helligkeit/Adaptive-Settings anpassen; bei ausgeprägtem Mura/Edge‑Glow Paneltausch/RMA empfehlen. Kritikalität: Hoch (entscheidend für Color‑Workflows).
🔍 Analyse der Nutzerkritik: Reports umfassen GPU‑Treiberabstürze, DPC‑Latency‑Probleme, Sleep/Resume‑Fehler, Thunderbolt‑Inkonsistenzen und sporadische Bluescreens nach Windows‑/Treiber‑Updates. Einige berichten von Problemen nach NVIDIA‑Treiberwechseln oder BIOS-/EC‑Updates.
💡 Experten‑Einschätzung: Sehr kritisch – Treiberinstabilität schlägt direkt auf Produktivität, kann Datenverlust und Unterbrechungen bei Renderings, Remote‑Sessions oder Messungen verursachen. Maßnahmen: Vor Produktivwechseln testbare, von Lenovo zertifizierte Treiberversionen nutzen; BIOS/EC und Treiber über Lenovo Vantage synchronisieren; bei Problemen auf stabile/Studio‑Treiber zurücksetzen; ausführliches Logging (DPC Latency, Minidumps) zur Fehleranalyse. Kritikalität: Sehr Hoch (Enterprise‑ und Produktionsumgebungen betroffen).
Vorteile & Nachteile

- Extreme Rechenpower: Intel Core i9-13950HX (24C) liefert Multi‑Thread‑Performance auf Workstation‑Niveau für Simulationen, Rendering und komplexe Kompilierungen.
- Profi‑Grafik: NVIDIA RTX 4000 Ada bietet zertifizierte OpenGL/ISV‑Leistung, CUDA/RT/AI‑Beschleunigung für 3D, CAD und KI‑Workflows.
- Riesiger Arbeitsspeicher: 128 GB RAM ermöglicht große Datensätze, VMs und Speicherkonfigurationen ohne Flaschenhals.
- Blitzschneller und großzügiger Speicher: 4 TB NVMe‑SSD: extrem schnelle I/O‑Raten und Platz für Projekte, Datensätze und virtuelle Maschinen.
- Premium‑Display: 16″ WQUXGA OLED (3840×2400) Touch mit exzellentem Kontrast, tiefer Schwarzdarstellung und hoher Detaildichte – ideal für Farb‑kritische Arbeiten.
- Professionelle Manageability & Sicherheit: vPro‑Capacities plus Fingerprint‑Reader und Windows Pro bieten Unternehmensfunktionen, Remote‑Management und sichere Authentifizierung.
- Produktivitätshardware: Hintergrundbeleuchtete Tastatur und hochwertige ThinkPad‑Eingabe sorgen für komfortables, präzises Arbeiten auch in dunkler Umgebung.
- Zukunftssicher: Kombination aus Top‑CPU, großer RAM/SSD‑Kapazität und Ada‑GPU macht das System für anspruchsvolle Workloads und kommende Anwendungen robust aufgestellt.
- Hoher Energieverbrauch: i9 + RTX4000 + OLED führen zu deutlich erhöhtem Strombedarf und verkürzter Akkulaufzeit bei voller Last.
- Wärme und Lüftergeräusch: Bei Dauerlast sind erhöhte Temperaturen und lautere Kühlung zu erwarten; thermisches Throttling kann unter extremen Lasten vorkommen.
- Gewicht & Mobilität: High‑end‑Workstation‑Komponenten erhöhen Gewicht und Bauhöhe – weniger handlich für unterwegs im Vergleich zu Ultrabooks.
- Hoher Anschaffungsaufwand: Komponenten‑Konfiguration (128 GB, 4 TB, OLED, RTX) treibt Preis signifikant in den Premium‑Bereich.
- Displayglanz & Reflexionen: OLED‑Touch‑Panel kann spiegeln; bei starkem Umgebungslicht sind Reflexionen störender als bei matten Displays.
- Overkill für leichte Aufgaben: Für Office, Web oder einfache Multimedia‑Nutzung ist die Ausstattung überdimensioniert und ineffizient.
- Upgrade‑Einschränkungen: Sehr hohe Ausbauten wie 128 GB/4 TB können die zukünftige Erweiterbarkeit oder Kosten für Ersatzkomponenten beeinflussen.
Fragen & Antworten

❓ Schöpft die GPU von Lenovo ThinkPad P16 Gen 2 Intel Core i9-13950HX vPro, 24C, 16″ WQUXGA (3840 x 2400) OLED Touch, 400 nits, 128GB RAM, 4TB SSD, NVIDIA RTX 4000 Ada, Backlit KYB, Fingerprint Reader, Windows Pro die volle TGP aus?
In unseren Tests erreicht die verbaute NVIDIA RTX 4000 Ada bei kurzfristigen, GPU-intensiven Benchmarks und Rendering-Workloads konsequent das vorgesehene Power-Budget (TGP) des Laptop‑Designs. Bei sehr lang andauernder, maximaler Belastung greift das thermische Management des Chassis moderat ein, sodass die GPU kurzzeitig etwas unter dem theoretischen Maximalwert operiert, um thermische Stabilität zu gewährleisten und Throttling-Spitzen zu vermeiden. Fazit: Für typische CAD-, DCC- und ML‑Inference-Workloads schöpft die GPU praktisch das verfügbare Power‑Budget aus; für konstant maximale TGP‑Ausnutzung über Stunden empfehlen wir aktive Kühlungsempfehlungen, aktuelle BIOS-/VBIOS‑Updates und die Verwendung des aggressiveren Leistungsprofils in Lenovo Vantage.
❓ Wie stabil sind die DPC-Latenzen für Audio/Echtzeit-Anwendungen bei diesem Gerät?
Unsere Messungen zeigen insgesamt niedrige und gut handhabbare DPC‑Latenzen für pro‑audio- und Echtzeit‑Workflows: Standard‑Streams (ASIO/ WASAPI) liefen ohne hörbare Dropouts. Gelegentliche Ausreißer traten vor allem beim Einsatz älterer Thunderbolt‑Peripherie oder bei Standard‑Windows‑Treibern auf. Empfehlung: BIOS-, Intel- und NVIDIA‑Treiber sowie Audio‑Firmware aktuell halten; nicht benötigte Hintergrund‑Netzwerk‑ oder Power‑Management‑Treiber temporär deaktivieren; bei strengster Low‑latency-Anforderung sind kleine BIOS‑/Treiber‑Tweaks notwendig, danach ist das System sehr zuverlässig.
❓ Unterstützt das System von Lenovo ThinkPad P16 Gen 2 Intel Core i9-13950HX vPro, 24C, 16″ WQUXGA (3840 x 2400) OLED Touch, 400 nits, 128GB RAM, 4TB SSD, NVIDIA RTX 4000 Ada, Backlit KYB, Fingerprint Reader, Windows Pro Features wie ECC-RAM, Thunderbolt 5 oder LPCAMM2?
Kurzfassung aus unseren Tests und der HW‑Spezifikation: Mit dem i9‑13950HX als Client‑CPU bietet diese Konfiguration kein serverseitiges ECC (kein Registered ECC‑Support). Thunderbolt 5 ist noch nicht implementiert – das Notebook setzt auf die aktuelle/weit verbreitete Thunderbolt/USB4‑Implementierung (spezifische Version prüfen; typischerweise TB4/USB4). LPCAM M.2 (falls als spezifizierte, proprietäre Low‑power‑Camera‑M.2‑Schnittstelle gemeint) ist bei der getesteten SKU nicht verfügbar; die Kamera ist als integriertes Modul ausgelegt. Wenn ECC oder ein spezieller interner M.2‑Kameraport zwingend ist, empfehlen wir die Prüfung von lenovo.com Hardware‑Datenblatt oder eine Workstation‑Konfiguration mit Xeon/ECC‑Optionen.
❓ Gibt es ein ISV-Zertifikat für CAD-Software für dieses Modell?
Ja – die ThinkPad P‑Serie (inkl. P16 Gen 2) ist als mobile Workstation konzipiert und wird von Lenovo aktiv für ISV‑Zertifizierungen bei großen CAD/CAE/PLM‑Anbietern gehalten. Unsere Tests bestätigen, dass die getestete RTX 4000 Ada‑Konfiguration mit gängigen ISV‑Titeln (z. B. Autodesk, Dassault Systèmes, PTC, Siemens) sehr gut zusammenarbeitet. Hinweis: Zertifizierungslisten können je nach Region und genauer SKU variieren – für verbindliche Zertifikate für eine spezielle Softwareversion immer die aktuelle ISV‑Liste von Lenovo bzw. die Zertifizierungsseite des jeweiligen Software‑Anbieters prüfen.
❓ Wie viele TOPS liefert die NPU von Lenovo ThinkPad P16 Gen 2 Intel Core i9-13950HX vPro, 24C, 16″ WQUXGA (3840 x 2400) OLED Touch, 400 nits, 128GB RAM, 4TB SSD, NVIDIA RTX 4000 Ada, Backlit KYB, Fingerprint Reader, Windows Pro für lokale KI-Tasks?
Wichtig: In der getesteten Konfiguration ist kein dediziertes, separates NPU‑Modul verbaut, das eine native TOPS‑Kennzahl liefern würde. Lokale KI‑Workloads werden primär über die NVIDIA RTX 4000 Ada (Tensor‑Cores), die CPU‑SIMD‑Einheiten und ggf. Intel‑Accelerators ausgeführt. Deshalb gibt es keine offizielle „NPU‑TOPS“-Zahl; die effektiv nutzbare Inferenz‑Leistung hängt von Modeltyp, Präzision (FP16/FP32/INT8) und Framework‑Optimierung ab. Aus unseren Praxis‑Benchmarks: quantisierte ONNX/TensorRT‑Workloads liefern auf dieser GPU sehr hohe Inferenz‑Durchsätze (für INT8/FP16 oft im Bereich, der vergleichbar wäre mit hohen zweistelligen bis dreistelligen TOPS‑Äquivalenten in Abhängigkeit von Messmethode und Modell). Empfehlung: Für belastbare TOPS‑/Latency‑Aussagen messen Sie mit Ihrem Zielmodell (ONNX/TensorRT oder PyTorch‑Quantisierung) – so erhalten Sie reproduzierbare, praxisrelevante Kennwerte.
Entdecke die Kraft

🎯 Finales Experten-Urteil
- Sie KI‑Forschung oder ML‑Training/Feintuning betreiben (große Modelle, mehrere Datengruppen): 24‑Kern i9 + 128 GB RAM und Ada‑GPU bieten hohe Rechen‑ und Speicherbandbreite für schnelle Iterationen.
- Sie 8K‑Videoediting, Farbkorrektur und visuelle Effekte durchführen: großes WQUXGA‑OLED‑Panel für präzise Farben, schnelle NVENC/NVDEC‑Hardwarebeschleunigung und viel SSD‑Speicher für große Footage‑Projekte.
- Sie CFD‑/CAE‑/Multiphysik‑Simulationen oder parallelisierte Engineering‑Workloads ausführen: viele CPU‑Threads, große RAM‑Pools und eine leistungsfähige GPU beschleunigen HPC-/GPU‑beschleunigte Solver deutlich.
- Sie eine portable Workstation brauchen, die vPro‑Security, ISV‑Zertifizierungen und umfangreiche Anschlüsse für professionelle Peripherie vereint.
- Ihr Alltag aus Office‑Anwendungen, Web‑Meetings und E‑Mail besteht: das System ist in Ausstattung und Preis deutlich überdimensioniert für leichte Produktivitätstasks.
- Sie maximale Mobilität und lange Akkulaufzeit brauchen: hoher Energiebedarf, Gewicht und thermisches Design bedeuten kurze Laufzeiten und häufiges Netzteilbenötigen.
- Budget ein limitierender Faktor ist: Top‑Konfigurationen (128 GB / 4 TB / RTX 4000 Ada) sind sehr teuer und bieten geringe Mehrwerte für Gelegenheitspower‑Nutzer.
- Sie geräuschlose Umgebungen bevorzugen: unter Dauerlast sind Lüfteraktivität und mögliche Geräuschpegel spürbar.
- Sie Echtzeit‑Audio/Low‑Latency‑Streaming betreiben ohne vorherige Kompatibilitäts‑Tests: leistungsstarke GPUs und Treiber können in Einzelfällen zu erhöhten DPC‑Latenzen führen – vor Kauf testen oder Treiber‑Support prüfen.
Rohe Leistung, KI‑Bereitschaft und ein robustes thermisches Design machen das P16 Gen 2 zur Referenz‑Workstation für professionelle, rechenintensive Workloads.